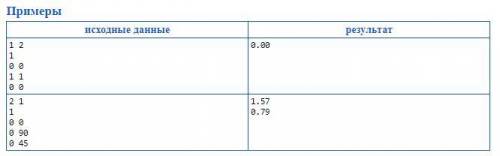
С++/С# Нужно написать алгоритм и решить задачу при его для любого из данных языков. Ограничение на память 64мб, ограничение на время 1с. В текстовом документе решение, которое не проходит тесты. Можно попробовать оптимизировать его, но у меня не выходит, либо написать другой алгоритм для поиска минимального пути
Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.)[4][5]. Применение этого стандарта позволяет закодировать очень большое число символов из разных систем письменности: в документах, закодированных по стандарту Юникод, могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, символы музыкальной нотной нотации, при этом становится ненужным переключение кодовых страниц[6].
Стандарт состоит из двух основных частей: универсального набора символов (англ. Universal character set, UCS) и семейства кодировок (англ. Unicode transformation format, UTF). Универсальный набор символов перечисляет допустимые по стандарту Юникод символы и присваивает каждому символу код в виде неотрицательного целого числа, записываемого обычно в шестнадцатеричной форме с префиксом U+, например, U+040F. Семейство кодировок определяет преобразования кодов символов для передачи в потоке или в файле.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII, и коды этих символов совпадают с их кодами в ASCII. Далее расположены области символов других систем письменности, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем[7]. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F (см. Кириллица в Юникоде)[8].
Итак, целевой язык - C++. Это значит мы - радостные обладатели технологии потоков, с коей мы будем производить весь ввод/вывод как при работе с файлами, так и при работе со стандартным вводом/выводом (консолью).
Ну а раз уж мы работаем с потоками, то будем делать это красивенько: создадим класс-обёртку для потока ввода, цель которого - поиск в этом потоке цитат и отправка их на поток вывода (который мы передаём).
[!] Стоит отметить, что по заданию не сказано, что есть разница между ' и ". Поэтому будем считать их одинаковыми.
[!] Внимание! Рядом с исполняемым файлом надо создать текстовый файл data.txt c текстом и цитатами.
Код
С++11
#include <iostream>#include <fstream>using std::cout;class QuotesFinder { std::istream &in_stream; bool is_it_in_quote = false;public: QuotesFinder() = delete; QuotesFinder(QuotesFinder&&) = default; QuotesFinder(QuotesFinder const&) = default; explicit QuotesFinder(std::istream &is) : in_stream(is) {} [[nodiscard]] bool eof() const { return in_stream.eof(); } // Вот тут происходит вся магия QuotesFinder& operator >> (std::ostream& out_stream) { char buffer; in_stream.get(buffer); //Получаем очередной символ из потока if (buffer == '\"' || buffer == '\'') { if (is_it_in_quote) { is_it_in_quote = false; out_stream << buffer; out_stream << "\n"; return *this; } is_it_in_quote = true; } if (is_it_in_quote) { out_stream << buffer; } return *this; }};int main() { std::ifstream file("data.txt"); // Открываем файл if (!file.is_open()) { cout << "File is not exits!"; return 1; } QuotesFinder finder(file); // Создаём обёртку из файлового потока while (!finder.eof()) // Пока не достигли конца потока finder >> cout; // переправляем очередной кусок информации в поток вывода}

Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.)[4][5]. Применение этого стандарта позволяет закодировать очень большое число символов из разных систем письменности: в документах, закодированных по стандарту Юникод, могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, символы музыкальной нотной нотации, при этом становится ненужным переключение кодовых страниц[6].
Стандарт состоит из двух основных частей: универсального набора символов (англ. Universal character set, UCS) и семейства кодировок (англ. Unicode transformation format, UTF). Универсальный набор символов перечисляет допустимые по стандарту Юникод символы и присваивает каждому символу код в виде неотрицательного целого числа, записываемого обычно в шестнадцатеричной форме с префиксом U+, например, U+040F. Семейство кодировок определяет преобразования кодов символов для передачи в потоке или в файле.
Коды в стандарте Юникод разделены на несколько областей. Область с кодами от U+0000 до U+007F содержит символы набора ASCII, и коды этих символов совпадают с их кодами в ASCII. Далее расположены области символов других систем письменности, знаки пунктуации и технические символы. Часть кодов зарезервирована для использования в будущем[7]. Под символы кириллицы выделены области знаков с кодами от U+0400 до U+052F, от U+2DE0 до U+2DFF, от U+A640 до U+A69F (см. Кириллица в Юникоде)[8].
с инета
Итак, целевой язык - C++. Это значит мы - радостные обладатели технологии потоков, с коей мы будем производить весь ввод/вывод как при работе с файлами, так и при работе со стандартным вводом/выводом (консолью).
Ну а раз уж мы работаем с потоками, то будем делать это красивенько: создадим класс-обёртку для потока ввода, цель которого - поиск в этом потоке цитат и отправка их на поток вывода (который мы передаём).
[!] Стоит отметить, что по заданию не сказано, что есть разница между ' и ". Поэтому будем считать их одинаковыми.
[!] Внимание! Рядом с исполняемым файлом надо создать текстовый файл data.txt c текстом и цитатами.
КодС++11
#include <iostream>#include <fstream>using std::cout;class QuotesFinder { std::istream &in_stream; bool is_it_in_quote = false;public: QuotesFinder() = delete; QuotesFinder(QuotesFinder&&) = default; QuotesFinder(QuotesFinder const&) = default; explicit QuotesFinder(std::istream &is) : in_stream(is) {} [[nodiscard]] bool eof() const { return in_stream.eof(); } // Вот тут происходит вся магия QuotesFinder& operator >> (std::ostream& out_stream) { char buffer; in_stream.get(buffer); //Получаем очередной символ из потока if (buffer == '\"' || buffer == '\'') { if (is_it_in_quote) { is_it_in_quote = false; out_stream << buffer; out_stream << "\n"; return *this; } is_it_in_quote = true; } if (is_it_in_quote) { out_stream << buffer; } return *this; }};int main() { std::ifstream file("data.txt"); // Открываем файл if (!file.is_open()) { cout << "File is not exits!"; return 1; } QuotesFinder finder(file); // Создаём обёртку из файлового потока while (!finder.eof()) // Пока не достигли конца потока finder >> cout; // переправляем очередной кусок информации в поток вывода}