В многонациональном и мультиязычном мире существует проблема международной коммуникации. Людей, свободно говорящих на многих языках, меньше, чем людей, которым требуется перевод речи собеседника, научных текстов или видеоматериалов. Для разрешения подобных проблем появились системы компьютерного перевода.
Прообразы систем компьютерного перевода появились в начале 1930-х годов, работали такие системы по принципу словарей: на вход механизму подавались специально подготовленные наборы слов, которые переводились машиной, результат интерпретировался человеком, создававшим из него осмысленный текст.
Первые системы компьютерного перевода появились после второй мировой войны, содержали списки переводов слов и небольшой набор правил грамматики. В первой публичной демонстрации машинного перевода (1954 год, Джорджтаун) использовалась система, основанная на словаре из 250 записей, и всего на 6 правилах грамматики. Несмотря на позитивный настрой разработчиков, значительное финансирование и интерес со стороны средств массовой информации, переводчик был скорее игрушкой, качество перевода было невысоким. В последующие годы предпринимались многочисленные попытки улучшить качество перевода.
В 1980-х годах обрели широкое рас микрокомпьютеры, на базе которых были созданы портативные компьютерные переводчики. Это подогрело интерес к системам компьютерного перевода со стороны промышленности и, как следствие, и мотивацию учёных. В это же время начали развиваться системы распознавания и генерации речи, что давало надежды на машинный перевод в режиме "on-air", во время разговора.
В настоящее время используется множество систем компьютерного перевода. К системам с заранее заданными правилами перевода добавляют статистические модели, самообучающиеся алгоритмы. Популярен подход с использованием нейронных сетей - алгоритмов, которые состоят из множества изменяющихся под действием обучения частей (нейронов), которые выдают ответ, интерпретируя сигналы, возвращаемые нейронами. Усложнения используемых алгоритмов позволяют получать результаты, приближенные к переводам переводчиков-людей.
В многонациональном и мультиязычном мире существует проблема международной коммуникации. Людей, свободно говорящих на многих языках, меньше, чем людей, которым требуется перевод речи собеседника, научных текстов или видеоматериалов. Для разрешения подобных проблем появились системы компьютерного перевода.
Прообразы систем компьютерного перевода появились в начале 1930-х годов, работали такие системы по принципу словарей: на вход механизму подавались специально подготовленные наборы слов, которые переводились машиной, результат интерпретировался человеком, создававшим из него осмысленный текст.
Первые системы компьютерного перевода появились после второй мировой войны, содержали списки переводов слов и небольшой набор правил грамматики. В первой публичной демонстрации машинного перевода (1954 год, Джорджтаун) использовалась система, основанная на словаре из 250 записей, и всего на 6 правилах грамматики. Несмотря на позитивный настрой разработчиков, значительное финансирование и интерес со стороны средств массовой информации, переводчик был скорее игрушкой, качество перевода было невысоким. В последующие годы предпринимались многочисленные попытки улучшить качество перевода.
В 1980-х годах обрели широкое распространение микрокомпьютеры, на базе которых были созданы портативные компьютерные переводчики. Это подогрело интерес к системам компьютерного перевода со стороны промышленности и, как следствие, и мотивацию учёных. В это же время начали развиваться системы распознавания и генерации речи, что давало надежды на машинный перевод в режиме "on-air", во время разговора.
В настоящее время используется множество систем компьютерного перевода. К системам с заранее заданными правилами перевода добавляют статистические модели, самообучающиеся алгоритмы. Популярен подход с использованием нейронных сетей - алгоритмов, которые состоят из множества изменяющихся под действием обучения частей (нейронов), которые выдают ответ, интерпретируя сигналы, возвращаемые нейронами. Усложнения используемых алгоритмов позволяют получать результаты, приближенные к переводам переводчиков-людей.
Основные проблемы у компьютерных переводчиков возникают с неоднозначностью перевода. Много слов имеют разные значения, в языках существуют разные диалекты, в которых одинаковые на вид понятия могут иметь противоположные значения. Человек при переводе может догадаться, о чём идёт речь, компьютер же сам "додумать" ничего не может, поэтому использует то, что уже знает. При переводе технических текстов, инструкций или устойчивых выражений системы компьютерного перевода почти всех выбирают верные варианты, исходя из контекста. В случае художественных текстов задача усложняется, в том числе из-за того, что определённые метафоры в культуре одного народа могут не совпадать с традициями другого. Поэтому качество перевода художественных текстов как правило ниже, чем всех остальных.
Использование самообучающихся алгоритмов позволяет улучшить качество перевода за счёт анализа новых источников. Часто это бывает полезным, но эту систему можно использовать, чтобы ухудшить качество перевода, сделать его нелепым. В интернете можно найти много примеров из онлайн-переводчиков компаний Goоgle и Яндeкс, например, когда-то "Константин Хабенский" переводилось на английский как "Keira Knightley" - Кира Найтли. Скорее всего, это было сделано интернет-троллями, часто поправлявшими правильный вариант на неправильный, из-за чего изменились настройки алгоритма перевода.
Системы компьютерного перевода входят в большую группу алгоритмов, занимающихся обработкой естественного языка. Их развитие людям как общаться между собой, получать информацию из иноязычных источников, так и научит компьютеры лучше понимать человека и его запросы, что повысит эффективность, простоту использования компьютера и увеличит возможные плюсы от такого взаимодействия.
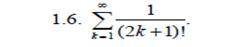
Прообразы систем компьютерного перевода появились в начале 1930-х годов, работали такие системы по принципу словарей: на вход механизму подавались специально подготовленные наборы слов, которые переводились машиной, результат интерпретировался человеком, создававшим из него осмысленный текст.
Первые системы компьютерного перевода появились после второй мировой войны, содержали списки переводов слов и небольшой набор правил грамматики. В первой публичной демонстрации машинного перевода (1954 год, Джорджтаун) использовалась система, основанная на словаре из 250 записей, и всего на 6 правилах грамматики. Несмотря на позитивный настрой разработчиков, значительное финансирование и интерес со стороны средств массовой информации, переводчик был скорее игрушкой, качество перевода было невысоким. В последующие годы предпринимались многочисленные попытки улучшить качество перевода.
В 1980-х годах обрели широкое рас микрокомпьютеры, на базе которых были созданы портативные компьютерные переводчики. Это подогрело интерес к системам компьютерного перевода со стороны промышленности и, как следствие, и мотивацию учёных. В это же время начали развиваться системы распознавания и генерации речи, что давало надежды на машинный перевод в режиме "on-air", во время разговора.
В настоящее время используется множество систем компьютерного перевода. К системам с заранее заданными правилами перевода добавляют статистические модели, самообучающиеся алгоритмы. Популярен подход с использованием нейронных сетей - алгоритмов, которые состоят из множества изменяющихся под действием обучения частей (нейронов), которые выдают ответ, интерпретируя сигналы, возвращаемые нейронами. Усложнения используемых алгоритмов позволяют получать результаты, приближенные к переводам переводчиков-людей.
Прообразы систем компьютерного перевода появились в начале 1930-х годов, работали такие системы по принципу словарей: на вход механизму подавались специально подготовленные наборы слов, которые переводились машиной, результат интерпретировался человеком, создававшим из него осмысленный текст.
Первые системы компьютерного перевода появились после второй мировой войны, содержали списки переводов слов и небольшой набор правил грамматики. В первой публичной демонстрации машинного перевода (1954 год, Джорджтаун) использовалась система, основанная на словаре из 250 записей, и всего на 6 правилах грамматики. Несмотря на позитивный настрой разработчиков, значительное финансирование и интерес со стороны средств массовой информации, переводчик был скорее игрушкой, качество перевода было невысоким. В последующие годы предпринимались многочисленные попытки улучшить качество перевода.
В 1980-х годах обрели широкое распространение микрокомпьютеры, на базе которых были созданы портативные компьютерные переводчики. Это подогрело интерес к системам компьютерного перевода со стороны промышленности и, как следствие, и мотивацию учёных. В это же время начали развиваться системы распознавания и генерации речи, что давало надежды на машинный перевод в режиме "on-air", во время разговора.
В настоящее время используется множество систем компьютерного перевода. К системам с заранее заданными правилами перевода добавляют статистические модели, самообучающиеся алгоритмы. Популярен подход с использованием нейронных сетей - алгоритмов, которые состоят из множества изменяющихся под действием обучения частей (нейронов), которые выдают ответ, интерпретируя сигналы, возвращаемые нейронами. Усложнения используемых алгоритмов позволяют получать результаты, приближенные к переводам переводчиков-людей.
Основные проблемы у компьютерных переводчиков возникают с неоднозначностью перевода. Много слов имеют разные значения, в языках существуют разные диалекты, в которых одинаковые на вид понятия могут иметь противоположные значения. Человек при переводе может догадаться, о чём идёт речь, компьютер же сам "додумать" ничего не может, поэтому использует то, что уже знает. При переводе технических текстов, инструкций или устойчивых выражений системы компьютерного перевода почти всех выбирают верные варианты, исходя из контекста. В случае художественных текстов задача усложняется, в том числе из-за того, что определённые метафоры в культуре одного народа могут не совпадать с традициями другого. Поэтому качество перевода художественных текстов как правило ниже, чем всех остальных.
Использование самообучающихся алгоритмов позволяет улучшить качество перевода за счёт анализа новых источников. Часто это бывает полезным, но эту систему можно использовать, чтобы ухудшить качество перевода, сделать его нелепым. В интернете можно найти много примеров из онлайн-переводчиков компаний Goоgle и Яндeкс, например, когда-то "Константин Хабенский" переводилось на английский как "Keira Knightley" - Кира Найтли. Скорее всего, это было сделано интернет-троллями, часто поправлявшими правильный вариант на неправильный, из-за чего изменились настройки алгоритма перевода.
Системы компьютерного перевода входят в большую группу алгоритмов, занимающихся обработкой естественного языка. Их развитие людям как общаться между собой, получать информацию из иноязычных источников, так и научит компьютеры лучше понимать человека и его запросы, что повысит эффективность, простоту использования компьютера и увеличит возможные плюсы от такого взаимодействия.