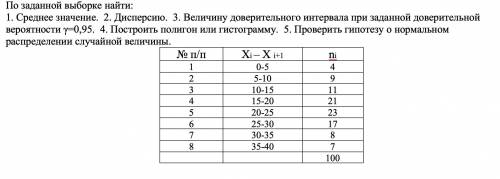
Для решения данной задачи, нам потребуются следующие шаги:
1. Среднее значение:
Среднее значение выборки можно найти, просуммировав все значения и поделив полученную сумму на количество элементов выборки. В данной задаче, у нас имеется выборка: {3, 5, 7, 8, 9, 11, 14, 15, 15, 16}.
Для нахождения среднего значения, сложим все значения выборки: 3 + 5 + 7 + 8 + 9 + 11 + 14 + 15 + 15 + 16 = 103.
Затем, разделим эту сумму на количество элементов в выборке, которых у нас 10:
Среднее значение = 103 / 10 = 10,3.
2. Дисперсия:
Чтобы найти дисперсию, нам необходимо вычислить среднее квадратичное отклонение (СКО). Сначала найдем разницу между каждым значением выборки и средним значением. Затем возведем разницы в квадрат и найдем среднее значение этих квадратов.
Разница между каждым значением выборки и средним значением:
(3-10,3)=-7,3; (5-10,3)=-5,3; (7-10,3)=-3,3; (8-10,3)=-2,3; (9-10,3)=-1,3; (11-10,3)=0,7; (14-10,3)=3,7; (15-10,3)=4,7; (15-10,3)=4,7; (16-10,3)=5,7.
Возведем эти разницы в квадрат:
(-7,3)^2=53,29; (-5,3)^2=28,09; (-3,3)^2=10,89; (-2,3)^2=5,29; (-1,3)^2=1,69; 0,7^2=0,49; 3,7^2=13,69; 4,7^2=22,09; 4,7^2=22,09; 5,7^2=32,49.
Складываем все эти значения:
53,29 + 28,09 + 10,89 + 5,29 + 1,69 + 0,49 + 13,69 + 22,09 + 22,09 + 32,49 = 190,10.
После этого, найдем среднее значение этих квадратов, разделив их сумму на количество элементов в выборке минус 1 (n-1). В данном случае, у нас 10 элементов, поэтому n-1 = 10-1 = 9.
Дисперсия = 190,10 / 9 = 21,12.
3. Величина доверительного интервала:
Величина доверительного интервала позволяет нам оценить, насколько близко среднее значение выборки к среднему значению генеральной совокупности. Для нахождения величины доверительного интервала, мы будем использовать формулу:
Доверительный интервал = среднее значение ± (Z * (СКО / √n)),
где Z - значение стандартной нормальной переменной, соответствующее заданной доверительной вероятности. Для доверительной вероятности γ=0,95, Z будет равно 1,96.
СКО - среднеквадратическое отклонение, а n - количество элементов в выборке.
Подставим значения из предыдущих расчетов в формулу:
Доверительный интервал = 10,3 ± (1,96 * (√21,12 / √10)).
Найдем корень от дисперсии и количество элементов в выборке:
√21,12 = 4,59; √10 = 3,16.
Заменим значения в формуле:
Доверительный интервал = 10,3 ± (1,96 * (4,59 / 3,16)).
Рассчитаем математическое выражение в скобках:
4,59 / 3,16 = 1,45.
Умножим это значение на 1,96:
1,45 * 1,96 = 2,85.
Теперь, мы можем найти доверительный интервал:
Доверительный интервал = 10,3 ± 2,85.
Следовательно, доверительный интервал будет равен: (7,45; 13,15).
4. Полигон или гистограмма:
Для построения полигона или гистограммы, возьмем значения из выборки и расположим их на оси Х в порядке возрастания. Затем, для каждого значения, на оси Y отметим количество раз, которое это значение встречается в выборке.
В нашем случае, значения выборки {3, 5, 7, 8, 9, 11, 14, 15, 15, 16} по оси X будут следующими: 3, 5, 7, 8, 9, 11, 14, 15, 15, 16.
А количество раз, которое каждое из этих значений встречается, будет выглядеть так: 1, 1, 1, 1, 1, 1, 1, 2, 1, 1.
Используя эти значения, можно построить полигон (линию, проходящую через все значения) или гистограмму, где каждому значению соответствует столбец с высотой, пропорциональной количеству раз его появления в выборке.
5. Проверка гипотезы о нормальном распределении:
Для проверки гипотезы о нормальном распределении случайной величины, мы можем использовать критерий Шапиро-Уилка. Он позволяет нам определить, является ли распределение близким к нормальному или нет.
Программный код для проверки гипотезы о нормальном распределении выборки на Python будет выглядеть следующим образом:
```python
import scipy.stats as stats
if p_value > significance_level:
print("Распределение близко к нормальному.")
else:
print("Распределение не является нормальным.")
```
В данном коде, мы используем функцию `shapiro()` из модуля `scipy.stats`, чтобы получить статистику критерия Шапиро-Уилка (`stat`) и p-значение (`p_value`). Затем, мы сравниваем полученное p-значение со значением уровня значимости (`significance_level`) и выводим результат о близости распределения к нормальному или его отличии от нормального.
ответ: это где конкретно, на бумагу, в прогге? В какой?
Объяснение:
1. Среднее значение:
Среднее значение выборки можно найти, просуммировав все значения и поделив полученную сумму на количество элементов выборки. В данной задаче, у нас имеется выборка: {3, 5, 7, 8, 9, 11, 14, 15, 15, 16}.
Для нахождения среднего значения, сложим все значения выборки: 3 + 5 + 7 + 8 + 9 + 11 + 14 + 15 + 15 + 16 = 103.
Затем, разделим эту сумму на количество элементов в выборке, которых у нас 10:
Среднее значение = 103 / 10 = 10,3.
2. Дисперсия:
Чтобы найти дисперсию, нам необходимо вычислить среднее квадратичное отклонение (СКО). Сначала найдем разницу между каждым значением выборки и средним значением. Затем возведем разницы в квадрат и найдем среднее значение этих квадратов.
Разница между каждым значением выборки и средним значением:
(3-10,3)=-7,3; (5-10,3)=-5,3; (7-10,3)=-3,3; (8-10,3)=-2,3; (9-10,3)=-1,3; (11-10,3)=0,7; (14-10,3)=3,7; (15-10,3)=4,7; (15-10,3)=4,7; (16-10,3)=5,7.
Возведем эти разницы в квадрат:
(-7,3)^2=53,29; (-5,3)^2=28,09; (-3,3)^2=10,89; (-2,3)^2=5,29; (-1,3)^2=1,69; 0,7^2=0,49; 3,7^2=13,69; 4,7^2=22,09; 4,7^2=22,09; 5,7^2=32,49.
Складываем все эти значения:
53,29 + 28,09 + 10,89 + 5,29 + 1,69 + 0,49 + 13,69 + 22,09 + 22,09 + 32,49 = 190,10.
После этого, найдем среднее значение этих квадратов, разделив их сумму на количество элементов в выборке минус 1 (n-1). В данном случае, у нас 10 элементов, поэтому n-1 = 10-1 = 9.
Дисперсия = 190,10 / 9 = 21,12.
3. Величина доверительного интервала:
Величина доверительного интервала позволяет нам оценить, насколько близко среднее значение выборки к среднему значению генеральной совокупности. Для нахождения величины доверительного интервала, мы будем использовать формулу:
Доверительный интервал = среднее значение ± (Z * (СКО / √n)),
где Z - значение стандартной нормальной переменной, соответствующее заданной доверительной вероятности. Для доверительной вероятности γ=0,95, Z будет равно 1,96.
СКО - среднеквадратическое отклонение, а n - количество элементов в выборке.
Подставим значения из предыдущих расчетов в формулу:
Доверительный интервал = 10,3 ± (1,96 * (√21,12 / √10)).
Найдем корень от дисперсии и количество элементов в выборке:
√21,12 = 4,59; √10 = 3,16.
Заменим значения в формуле:
Доверительный интервал = 10,3 ± (1,96 * (4,59 / 3,16)).
Рассчитаем математическое выражение в скобках:
4,59 / 3,16 = 1,45.
Умножим это значение на 1,96:
1,45 * 1,96 = 2,85.
Теперь, мы можем найти доверительный интервал:
Доверительный интервал = 10,3 ± 2,85.
Следовательно, доверительный интервал будет равен: (7,45; 13,15).
4. Полигон или гистограмма:
Для построения полигона или гистограммы, возьмем значения из выборки и расположим их на оси Х в порядке возрастания. Затем, для каждого значения, на оси Y отметим количество раз, которое это значение встречается в выборке.
В нашем случае, значения выборки {3, 5, 7, 8, 9, 11, 14, 15, 15, 16} по оси X будут следующими: 3, 5, 7, 8, 9, 11, 14, 15, 15, 16.
А количество раз, которое каждое из этих значений встречается, будет выглядеть так: 1, 1, 1, 1, 1, 1, 1, 2, 1, 1.
Используя эти значения, можно построить полигон (линию, проходящую через все значения) или гистограмму, где каждому значению соответствует столбец с высотой, пропорциональной количеству раз его появления в выборке.
5. Проверка гипотезы о нормальном распределении:
Для проверки гипотезы о нормальном распределении случайной величины, мы можем использовать критерий Шапиро-Уилка. Он позволяет нам определить, является ли распределение близким к нормальному или нет.
Программный код для проверки гипотезы о нормальном распределении выборки на Python будет выглядеть следующим образом:
```python
import scipy.stats as stats
data = [3, 5, 7, 8, 9, 11, 14, 15, 15, 16]
# Проверка гипотезы о нормальном распределении
stat, p_value = stats.shapiro(data)
significance_level = 0.05
if p_value > significance_level:
print("Распределение близко к нормальному.")
else:
print("Распределение не является нормальным.")
```
В данном коде, мы используем функцию `shapiro()` из модуля `scipy.stats`, чтобы получить статистику критерия Шапиро-Уилка (`stat`) и p-значение (`p_value`). Затем, мы сравниваем полученное p-значение со значением уровня значимости (`significance_level`) и выводим результат о близости распределения к нормальному или его отличии от нормального.